PhD defense
Public PhD defense Victor Dheur : Distribution-Free and Calibrated Predictive Uncertainty in Probabilistic Machine Learning
Victor Dheur will hold his public PhD defense on Thursday 11 December 2025 at 17h. Instead of just asking an AI for a single answer, it is often safer to ask for probabilistic predictions such as a range of possibilities. Victor Dheur designed algorithms that ensure these predictions are both reliable and informative, helping decision-makers across diverse applications. His dissertation is supervised by Prof. Souhaib Ben Taieb and Stéphane Dupont.
 Date : Thursday December 11, 2025 at 17h, Mirzakhani Room (De Vinci Building), Plaine de Nimy, Av. Maistriau 15, 7000 Mons
Date : Thursday December 11, 2025 at 17h, Mirzakhani Room (De Vinci Building), Plaine de Nimy, Av. Maistriau 15, 7000 Mons
Title : Distribution-Free and Calibrated Predictive Uncertainty in Probabilistic Machine Learning
Abstract :
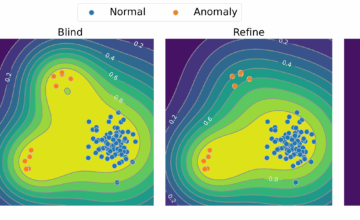
Machine learning models are increasingly deployed in high-stakes domains such as healthcare and autonomous systems, where decisions carry significant risks. Probabilistic machine learning is valuable in these settings, as it quantifies predictive uncertainty, notably by generating probabilistic predictions. We focus on regression, where the goal is to predict one or more continuous outputs given a set of inputs. In this context, we consider two main forms of uncertainty representation: predictive distributions, which assign probabilities to possible output values, and prediction sets, which are designed to contain the true output with a pre-specified probability. For these predictions to be reliable and informative, they must be calibrated and sharp, i.e., statistically consistent with observed data and concentrated around the true value.
 In this thesis, we develop distribution-free regression methods to produce calibrated and sharp probabilistic predictions using neural network models. We consider both single-output and the less-explored multi-output regression settings. Specifically, we develop and study recalibration, regularization, and conformal prediction (CP) methods. The first adjusts predictions after model training, the second augments the training objective, and the last produces prediction sets with finite-sample coverage guarantees.
In this thesis, we develop distribution-free regression methods to produce calibrated and sharp probabilistic predictions using neural network models. We consider both single-output and the less-explored multi-output regression settings. Specifically, we develop and study recalibration, regularization, and conformal prediction (CP) methods. The first adjusts predictions after model training, the second augments the training objective, and the last produces prediction sets with finite-sample coverage guarantees.For single-output regression, we conduct a large-scale experimental study to provide a comprehensive comparison of these methods. The results reveal that post-hoc approaches consistently achieve superior calibration. We explain this finding by establishing a formal link between recalibration and CP, showing that recalibration also benefits from finite-sample coverage guarantees. However, the separate training and recalibration steps typically lead to degraded negative log-likelihood. To address this issue, we develop an end-to-end training procedure that incorporates the recalibration objective directly into learning, resulting in improved negative log-likelihood while maintaining calibration.
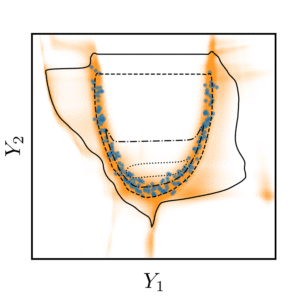
For multi-output regression, we conduct a comparative study of CP methods and introduce new classes of approaches that offer novel trade-offs between sharpness, compatibility with generative models, and computational efficiency. A key challenge in CP is achieving conditional coverage, which ensures that coverage guarantees hold for specific inputs rather than only on average. To address this, we propose a method that improves conditional coverage using conditional quantile regression, thereby avoiding the need to estimate full conditional distributions. Finally, for tasks requiring a full predictive density, we introduce a recalibration technique that operates in the latent space of invertible generative models such as conditional normalizing flows. This approach yields an explicit, calibrated multivariate probability density function. Collectively, these contributions advance the theory and practice of uncertainty quantification in machine learning, facilitating the development of more reliable predictive systems across diverse applications.